14829
741
RabbitMQ vs Apache Kafka
Если вы раздумываете, что лучше использовать - Kafka или RabbitMQ, читайте далее, чтобы узнать о различных архитектурах и подходах, лежащих в основе этих инструментов, о том, как они по-разному обрабатывают сообщения, а также о преимуществах и недостатках их использования. Мы рассмотрим лучшие случаи использования каждого из этих инструментов, а также расскажем о том, в каких случаях предпочтительнее использовать комплексное решение для обработки потоков.
Apache Kafka и RabbitMQ - это две системы pub/sub с открытым исходным кодом и коммерческой поддержкой, которые активно используются различными компаниями. RabbitMQ - это более старый инструмент, выпущенный в 2007 году и являвшийся основным компонентом в системах обмена сообщениями и SOA. Сегодня он также используется для потоковой передачи данных. Kafka - более новый инструмент, выпущенный в 2011 году, который с самого начала был создан для потоковых сценариев.
Что такое RabbitMQ?
RabbitMQ - это брокер сообщений общего назначения, который поддерживает такие протоколы, как MQTT, AMQP и STOMP. Он может работать с высокопроизводительными сценариями использования, такими как обработка онлайн-платежей. Он может обрабатывать фоновые задания или выступать в качестве брокера сообщений между микросервисами.
Что такое Apache Kafka?
Kafka - это шина сообщений, разработанная для высокопроизводительного воспроизведения данных и потоков. Также это надежный брокер сообщений, который позволяет приложениям обрабатывать, сохранять и повторно обрабатывать потоковые данные. Kafka имеет простой подход к маршрутизации, который использует ключ маршрутизации для отправки сообщений в тематический поток (topic).
Архитектура RabbitMQ
Основные компоненты RabbitMQ можно увидеть на рисунке ниже: 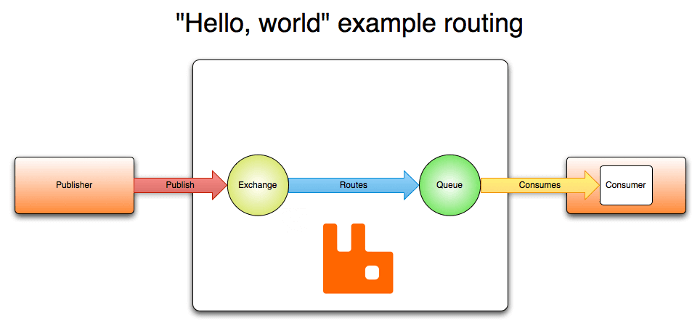
Как и другие брокеры сообщений, RabbitMQ получает сообщения от приложений, которые их публикуют - известных как производители или издатели. Внутри системы сообщения принимаются на обменниках - своеобразных виртуальных "почтовых отделениях", которые направляют сообщения в буферы хранения, называемые очередями. Приложения, которые читают сообщения, известные как потребители или подписчики, могут подписаться на эти очереди, чтобы получать последние данные, поступающие в "почтовые ящики".
Ключевыми особенностями RabbitMQ являются:
- Брокер сообщений общего назначения - использует различные варианты шаблонов связи запрос/ответ, точка-точка и pub-sub.
- Модель "умный брокер / тупой потребитель" - согласованная (consistent) доставка сообщений потребителям, примерно с той же скоростью, с какой брокер отслеживает состояние потребителя.
- Зрелая платформа - хорошо поддерживается, доступна для Java, клиентских библиотек, .NET, Ruby, node.js. Предлагаются десятки плагинов.
- Коммуникация - может быть синхронной или асинхронной.
- Сценарии развертывания: предоставляет сценарии распределенного развертывания.
- Объединение нескольких узлов в кластеры - не полагается на внешние сервисы, однако специальные плагины для формирования кластеров могут использовать DNS, API, Consul и т.д.
Архитектура Apache Kafka
Ниже показаны основные компоненты кластера Kafka:
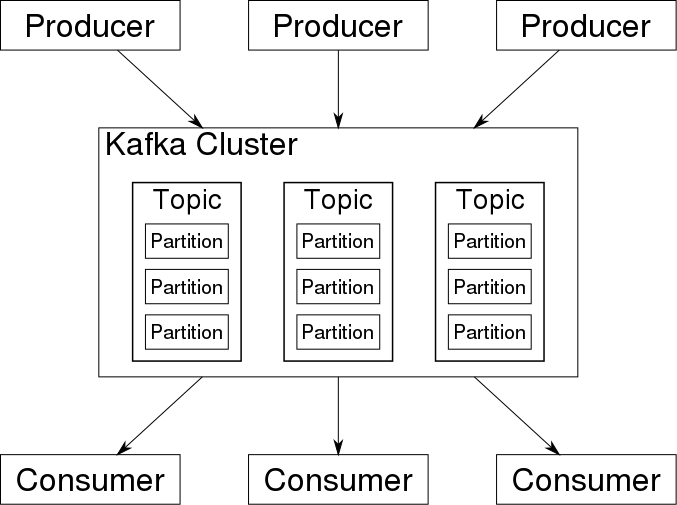
Производители и потребители здесь одни и те же - приложения, которые публикуют и читают сообщения о событиях соответственно. Как мы уже говорили, при обсуждении примеров использования Kafka, событие - это сообщение с данными, описывающими событие, например, регистрация нового пользователя в мобильном приложении. События ставятся в очередь в темах Kafka, и несколько потребителей могут подписаться на одну и ту же тему. Темы далее делятся на разделы, которые разделяют данные между брокерами для повышения производительности.
К важным особенностям Kafka относятся:
- Платформа для публикации-подписки сообщений и потоков большого объема - долговечная, быстрая и масштабируемая.
- Долговечное хранилище сообщений - Kafka ведет себя как журнал, запущенный в серверном кластере, который хранит потоки записей в темах (категориях).
- Сообщения состоят из значения, ключа и метки времени.
- Модель "тупой брокер / умный потребитель" (dumb broker / smart consumer) - не пытается отследить, какие сообщения прочитаны потребителями, и сохраняет только непрочитанные сообщения. Kafka хранит все сообщения в течение определенного периода времени.
- Управляется внешними службами - во многих случаях это Apache Zookeeper.
Подход pull vs push
Одно из важных различий между Kafka и RabbitMQ заключается в том, что первый основан на принципе pull, а второй - на принципе push. В системах, основанных на принципе pull, брокеры ждут, пока потребитель запросит данные ("pull"); если потребитель опаздывает, он может наверстать упущенное позже. В системах на основе push сообщения немедленно отправляются любому подписанному потребителю. Это может привести к тому, что эти два инструмента будут вести себя по-разному в некоторых обстоятельствах.
Apache Kafka: подход на основе pull
В Kafka используется модель pull. Потребители запрашивают пакеты сообщений с определенного смещения. Kafka допускает long-pooling, что предотвращает зацикливание, когда нет ни одного сообщения после смещения, и агрессивно сортирует сообщения для поддержки этого.
Модель pull логична для Kafka из-за разделенной структуры данных. Kafka обеспечивает порядок сообщений в разделе без конкурирующих потребителей. Это позволяет пользователям использовать пакетную передачу сообщений для эффективной доставки сообщений и повышения пропускной способности.
RabbitMQ: подход на основе push
RabbitMQ использует модель push и останавливает переполнение потребителей с помощью лимита предварительной выборки, определенного для потребителя. Это может быть использовано для обмена сообщениями с низкой задержкой.
Целью модели push является индивидуальное и быстрое распределение сообщений, чтобы обеспечить равномерное распараллеливание работы и обработку сообщений примерно в том порядке, в котором они поступили в очередь. Однако это также может вызвать проблемы в случаях, когда один или несколько потребителей "умерли" и больше не получают сообщений.
| Инструмент | Apache Kafka | RabbitMQ |
|---|---|---|
| Упорядочивание сообщений | Обеспечивает упорядочивание сообщений благодаря разбиению на разделы. Сообщения отправляются в темы по ключу сообщения | Не поддерживается |
| Срок жизни сообщений | Kafka - это журнал, что означает, что по умолчанию он сохраняет сообщения. Вы можете управлять этим, задав политику хранения. | RabbitMQ - это очередь, поэтому сообщения удаляются после их потребления, и обеспечивается подтверждение. |
| Гарантия доставки | Сохраняет порядок только внутри раздела. В разделе Kafka гарантирует, что вся партия сообщений либо провалится, либо пройдет. | Не гарантирует атомарность, даже в отношении транзакций с одной очередью. |
| Приоритет сообщений | Не поддерживается | В RabbitMQ вы можете указать приоритеты сообщений и сначала потреблять сообщения с высоким приоритетом. |
Производительность Kafka в сравнении с RabbitMQ
Kafka предлагает гораздо более высокую производительность, чем брокеры сообщений типа RabbitMQ. Он использует последовательный дисковый ввод-вывод для повышения производительности, что делает его подходящим вариантом для реализации очередей. Он может достигать высокой пропускной способности (миллионы сообщений в секунду) при ограниченных ресурсах, что необходимо для использования в больших данных (Big Data).
RabbitMQ также может обрабатывать миллион сообщений в секунду, но требует больше ресурсов (около 30 узлов). Вы можете использовать RabbitMQ для многих тех же целей, что и Kafka, но вам придется комбинировать его с другими инструментами, такими как Apache Cassandra.
Примеры использования Apache Kafka
Apache Kafka предоставляет сам брокер и был разработан для сценариев обработки потоков. Недавно он добавил Kafka Streams, клиентскую библиотеку для создания приложений и микросервисов. Apache Kafka поддерживает такие сценарии использования, как метрики, отслеживание активности, агрегация журналов, обработка потоков, журналы фиксации и поиск событий.
Для Kafka особенно подходят следующие сценарии обмена сообщениями:
- Потоки со сложной маршрутизацией, пропускной способностью 100 000/сек событий или более, с упорядочиванием "хотя бы один раз".
- Приложения, которым требуется история потока, доставляемая в разбитом на части порядке "хотя бы один раз". Клиенты могут видеть "повтор" потока событий.
- Поиск событий, моделирование изменений в системе как последовательности событий.
- Потоковая обработка данных в многоступенчатых конвейерах. Конвейеры генерируют графики потоков данных в реальном времени.
Случаи использования RabbitMQ
RabbitMQ можно использовать, когда веб-серверы должны быстро отвечать на запросы. Это устраняет необходимость выполнять ресурсоемкие действия, пока пользователь ожидает результата. RabbitMQ также используется для передачи сообщения различным получателям для потребления или для распределения нагрузки между работниками при высокой нагрузке (20 000+ сообщений/секунду).
Сценарии, для которых можно использовать RabbitMQ:
- Приложения, которым необходима поддержка устаревших протоколов, таких как STOMP, MQTT, AMQP, 0-9-1.
- Гранулярный контроль над согласованностью/набором гарантий на основе каждого сообщения
- Сложная маршрутизация к потребителям
- Приложения, которым необходимы различные возможности публикации/подписки, запроса/ответа "точка-точка".
Kafka и RabbitMQ: подведение итогов
В этом руководстве рассмотрены основные различия и сходства между Apache Kafka и RabbitMQ. Оба могут потреблять несколько миллионов сообщений в секунду, хотя их архитектуры отличаются, и каждый из них лучше работает в определенных средах. RabbitMQ управляет своими сообщениями почти в памяти, используя большой кластер (30+ узлов). По сравнению с ним, Kafka использует последовательные операции ввода-вывода на диск и, таким образом, требует меньше оборудования.
